こんにちは、開発部モバイルアプリチームの小関です。
普段は求人飲食店ドットコムのiOS・Androidアプリの開発をしている私ですが、昨年4月に設立された「GPTプロジェクトチーム」にも参加しており、この1年でより一般的にも身近になってきた生成AIをサービスや普段の業務に使えないかと模索する仕事もする日々です。
今回は、そんな「GPTプロジェクト」の一環で作成した社内アシスタントBotによって、ナレッジの検索しづらさを解決しようとした事例をご紹介しようと思います。
GPTプロジェクトとは
弊社では2023年4月から、CTO直下に「GPTプロジェクトチーム」を新設して(*1)、ChatGPTのような生成AIを活用する取り組みを進めています。
このプロジェクトでは、弊社が運営するサービスや社内業務に対して生成AI技術を適用し、飲食店の業務効率化や負荷削減を図ることを目的として活動しています。
チーム発足まもない頃は、そもそも生成AIとはどう動いているのだろうといった部分や、ChatGPTなどの生成AIサービスはどういった形で利用でき、どのような場面に適用することができるのかを探るところから行っていました。
生成AI自体は様々な種類がありますが、手始めに取り組むものとしてはやはりChatGPTからだろうとなり、APIの利用方法やLangChainという文章生成に関わるライブラリを調べるところから行い、この1年間でいくつか、ChatGPTを組み込んだツールや機能の開発を行いました。
今回はその中から、社内アシスタントBotを作ったことでナレッジ検索がしやすくなった事例を紹介していきます。
社内アシスタントBot 第一弾「ナレット」
弊社の社内ルールや労務関連の情報をまとめたナレッジはGoogleサイトで管理をしているのですが、ナレッジが存在するかを調べるときに検索ワードが適切に選定することが難しかったり、それらしいキーワードで調べたときに本来見たいはずのナレッジが上位にでてこなかったりする課題がありました。
そんな中、他社の事例でチャットツールを経由したナレッジ検索のやり方が公開されており(*2)、弊社でもそれを参考にして作ることでこの課題をクリアすることができるのではないかという話がチーム内で挙がり、実際に開発に至りました。
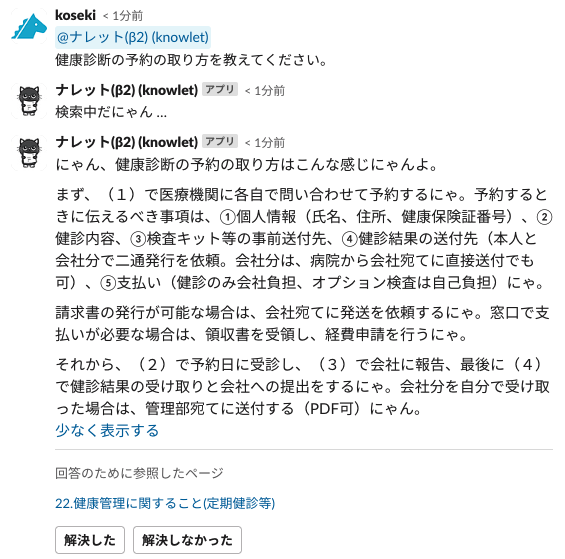
そうして作られた社内アシスタントBotは「ナレット」と名付けられ、ナレットに対してメンションをつけて質問を投げかけると、質問に類似したナレッジ記事から必要な箇所を情報として引っ張ってきて、その情報を元に質問に答えてくれるといった、まさにほしかった仕組みが完成したのでした。
(ナレッジ+キャットからついた名前のとおりに猫キャラを付与しています)
このBotの良い点は、適切なナレッジを検索するためのキーワードがある程度曖昧でも、自然言語で質問をして検索ができるところにあります。
また、参照したナレッジがリンクで提示されるため、そのナレッジにアクセスして、より詳しい情報を得ることもできますし、正しい情報を言っているのかどうかも、参照したナレッジが適切そうかどうかである程度判断することができます。
本当に正しいのだろうか?という回答の際には、大半が関係のないナレッジを参照してしまったことによるもののため、その際には質問の聞き方を変えてみることで、本来知りたかった情報を得られるということもありました。
回答は必ずしも正しいとはいえないため、最終的には質問者がソースまで見て判断することを一応推奨しているのですが、ある程度は正しいナレッジが参照されていれば適切な回答ができるようになっています。
また、回答にフィードバックボタンをつけて意図どおり動作しているかを把握できるようにしています(適切な回答が得られなかった際にGPTプロジェクトメンバーがサポートを行い、質問の仕方をアドバイスしたり、ナレッジがないことで回答できていなければナレッジを作成・更新してもらうよう働きかける想定でつけた機能です)。
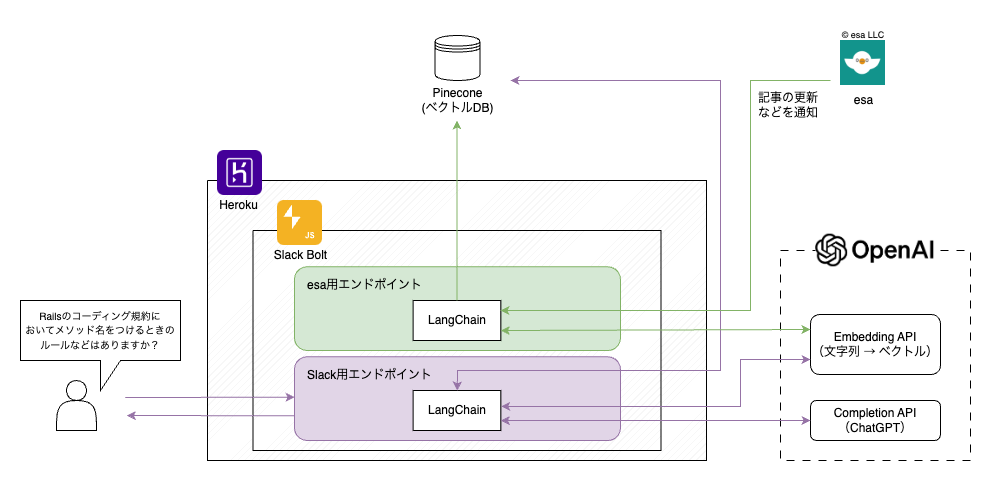
ここからはシステム的な話になりますが、実際に組んだ構成は以下のようになりました。
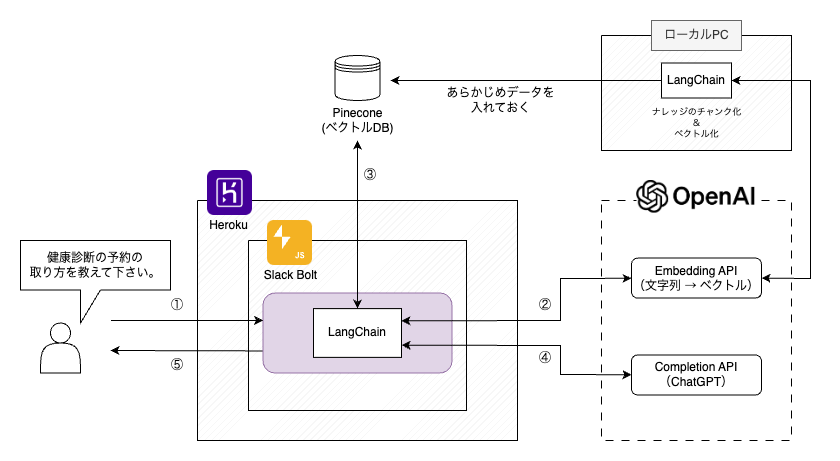
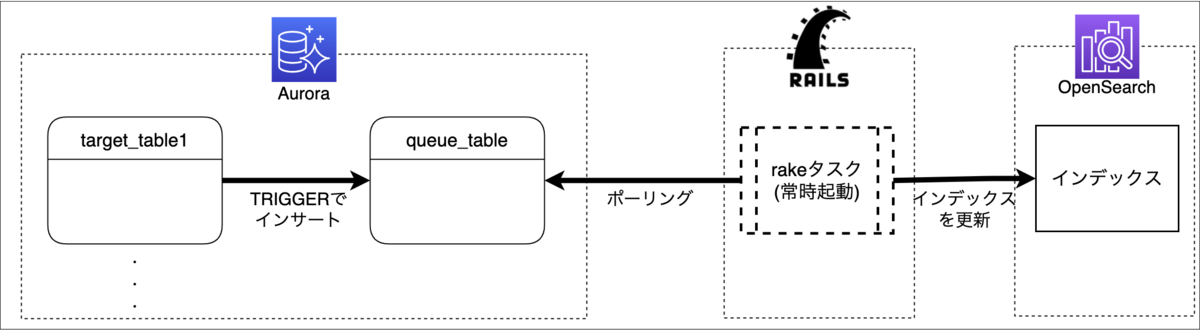
中心となっているのは、Slackが提供する Node.jsベースのフレームワークの Bolt for JavaScript を使って構築したアプリケーションで、実験的に動かしたいということもあり、PaaSのherokuを利用して動かしています。
また、今回はChatGPTを利用するにあたり、「LangChain」というChatGPTなどの大規模言語モデル(LLM)を使いやすくするためのフレームワークも併せて利用しています。
このLangChainはTypeScriptかPythonの形で提供されていましたが、社内的にもGPTプロジェクトメンバー的にもTypeScriptのほうが都合が良かったため、Slackアプリケーションも含めて言語はTypeScriptで統一して、このような構成になりました。
全体的な処理の流れとしては、
① Slackでナレット宛のメンションとともに質問をすると、Webhookによってアプリケーションにその情報が送られる
② 質問文をベクトル化する
③ 質問文に近い内容のナレッジがないかを、②のベクトルを使ってナレッジのベクトルDBに対して問い合わせる
④ ③で得た検索結果上位数件のナレッジの情報と質問文を組み込んだプロンプトでChatGPTに回答を作成してもらう
⑤ Slackの質問のスレッドに対して、④を返信する
となっています。
この中にでてくるナレッジが格納されたDBにはPineconeを利用しており、あらかじめGoogleサイトから取得したナレッジデータを一定の文量で区切って(チャンク化)、それをOpenAIのEmbedding APIにてベクトル化したデータを保存しています。
チャンク化するデータサイズは、大きすぎると最終的にChatGPTに渡す情報量が大きすぎることで当時は最大文字数の関係で扱いづらかったり課金額が増えてしまう課題につながり、小さすぎても情報が限定されることで質問に似ているかどうかの検索マッチ度がブレてしまって適切なデータが参照できないため、ここの調整には時間をかけて実験を重ね、ちょうどよいサイズを模索しました。
(最近では、ChatGPTに渡せる最大情報量(=トークン量)がかなり拡張され、課金額も安くなっているので昔よりもこのサイズは大きくしても問題なくなってきています)
こうして作られたナレットですが、単純にナレットを利用することでナレッジが検索しやすくなったこと以外にも、古いナレッジを放置するリスクがより高まったことで、なるべく更新をしようとする動きが働いたこともプラスの一面でした。
ちなみにChatGPTに詳しい方であればお気づきのとおり、このように大量の文章データを元にChatGPTに質問に回答させるようなことは、現在はChatGPT単体で解決できるようになっており、Assistantsという機能で提供されています。
ただし、柔軟なカスタマイズはできないので、ベクトルデータに対してタグを付与することや、引用元のURLを表示したりすることなどは工夫が必要になりそうではあり、今の構成を変えるほどではないとも考えています。
社内アシスタントBot 第二弾「さえずり」
弊社ではナレッジサービス・ツールをいくつか利用しており、部署などによっても使い分けをしています。
その中でも、エンジニア、デザイナー、ディレクターが利用するesa.ioというナレッジサービスがあり、業務に関するナレッジを保存したり、普段の会議での議事録としても利用しています。
そんなesaには、弊社が運営するサービスの知識や、開発における知見・ルールなどがまとめられており、前述のナレットのナレッジデータをesaにしたバージョンを作れないかという話が挙がったため、作成することになりました。
アプリケーションの全体的な仕組み自体は流用ができ、ナレッジを保存するベクトルDBの内容を社内ナレッジではなくesaの記事に変えるだけで済むといった具合に、比較的に容易に完成に至り、この新しいBotにはesaのサービスキャラクターの鳥から連想して「さえずり」という名前が付けられました。
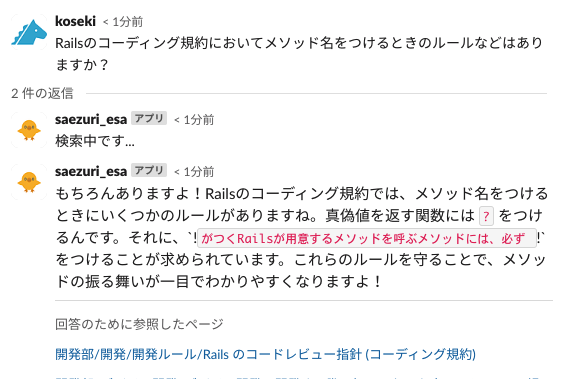
ただ、社内ナレッジはGoogleサイトの都合上、手動でデータを定期的に更新しているのですが、社内ナレッジの更新頻度が低いためにある程度許容できた部分でした。
esaに関しては基本的には毎日誰かがいろいろなナレッジを最新化したり、新規記事作成を行っており、更新間隔は短いほうが好ましかったことと、esaそのものにWebhookの機能があったため、更新や新規作成などをリアルタイムに受け取ってDB側も更新できそうだというところで、ナレットよりも少し広がったこのようなシステム構成となりました。
やはり、労務などのルールに関する疑問よりも実業務における疑問のほうが発生しやすいこともあり、ナレット以上にさえずりは利用されているのを見かけます。
また、ナレットが任意のチャンネル内でしか利用できないのに対して、さえずりはDMでクローズドに質問ができる点も良いところのため、ナレットも同様にDMで利用できるようにすることを検討しています(DMでのやりとりの際にはログが残らないようにも設定をしています)。
おわりに
GPTプロジェクトではこの1年で他にも、求人@インテリアデザインにおける職務経歴例自動生成機能のリリース(*3)に協力したりと、ChatGPTを活用した試みをいくつか行ってきました。
最近は、Claude 3というLLMがGPT-4を超えているのではないかと話題になっていたり、まだまだこの領域は目まぐるしく進化をしている毎日ですが、プロジェクトチームではChatGPTのみに限らずに多くの生成AIの活用を模索していきたいと考えています。
この1年は小さい改善を中心に検証を行って、社内でのノウハウも少しずつ溜まってきたため、今後はLLMを利用した大きい改善に挑戦していくフェーズになっていきます。
これからも飲食に関わる方々へ、より価値を提供できるような開発を行っていきたいと思います。
*1:プレスリリース 「飲食店ドットコム」が生成型AIを活用したサービス開発を開始 ~ CTO直下に「GPTプロジェクトチーム」を新設 ~
*2:こちらのSTORESさんの事例になります。大変参考になりました。 → ChatGPTを使った社内ドキュメントを読み込んで回答できるアシスタントBotを作りました!|howdy39