はじめまして。開発部の深野です。
今回は飲食店ドットコムの中のスカウト対象者検索という、サービス内でも一番DB負荷の高かった機能にOpenSearchを導入したので、導入時に検討したことと導入結果を紹介します。
シンクロ・フードのエンジニアブログでは、以前にも求人飲食店ドットコムの求人検索という機能にOpenSearchという全文検索エンジンを導入したことを紹介したことがあります。そのため、OpenSearchについて詳しく知りたい方は是非こちらの記事を先にお読みください。
はじめに
以前、弊社で最も頻繁に利用される機能である求人サイトの求人検索機能に全文検索エンジンであるOpenSearchを導入し、その高速化を図りました。
その結果として求人検索機能の高速化とDB負荷の低減という結果を得られたので、今回は新たな課題に取り組むことにしました。
具体的には、弊社のサービスでMySQLへの負荷が一番大きかったスカウト対象者検索機能にOpenSearchを導入することで、データベースの負担を軽減し、検索処理のさらなる改善を目指しました。
多くの求人サービスにはスカウトという仕組みがあり、求職者の方から会社へ応募するだけではなく、会社の方から求職者の方へ向けて自社を受けてみないかどうか勧誘することができると思います。飲食店ドットコムのスカウト対象者検索機能もこのようなことを実現するための機能であり、求職者の方の職務経歴や希望する勤務地を検索して求人飲食店ドットコム会員をスカウトすることが可能です。
導入の背景
元々のスカウト対象者検索機能は、以下のような問題を抱えた実装になっていました。
- 複数のテーブルにまたがる複雑な検索処理:一度のSQLクエリではなく、複数のSQL実行というステップを踏んで徐々に対象のスカウト対象者を絞り込む方式で実装されていた
- ページング機能のためのフルスキャン:検索条件に合致する件数を取得する
COUNT(*)がフルスキャンしており、実行時間が大きくかかっていた - 正規化されていないテーブルとカンマ区切りのカラム:一部のテーブルでは歴史的経緯によりカンマ区切りのカラムが使用されていることから、FIND_IN_SET関数を用いた検索が行われており、パフォーマンス面の問題を起こしていた
- フリーワード検索機能:部分一致のフリーワードが機能的に必要になったことで、LIKEによる部分一致の検索というパフォーマンス的にはあまり良くない実装が必要になっていた
これらから、アクセス量が増加するとすぐにデータベースのリソースを圧迫し、レスポンスタイムが著しく低下することがあり、最悪の場合システム障害につながることもありました。また、レスポンスタイムのさらなる劣化を避けるため、新機能の追加が一部制限されるという問題も抱えていました。過去にはOpenSearchを導入せずに高速化しようと試みたこともあったようなのですが、そのアプローチには限界がありそうなのでどうせこの問題に向き合う(=検索機能の再実装を行う)なら全文検索エンジンを利用したいという考えがあり、今回のOpenSearch導入に至りました。
MySQLからOpenSearchへのデータ同期方法
データ同期のためのシステム構成は以下の通りです:
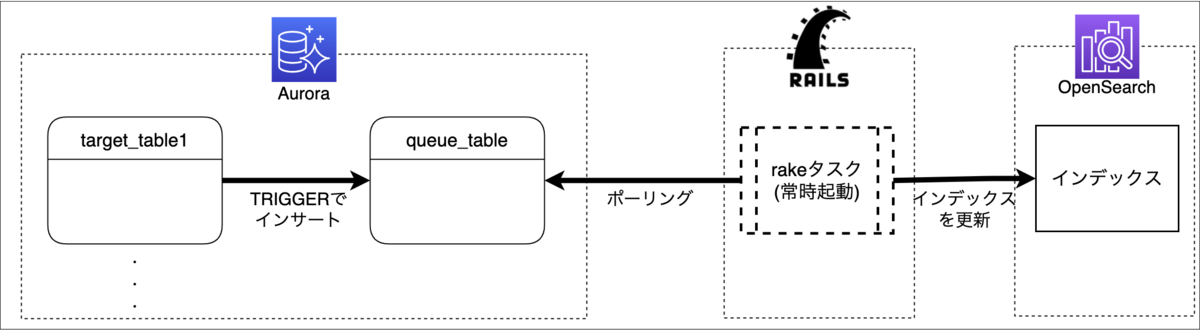
検索のために必要なテーブルはスカウト対象者のテーブルやその関連テーブルを含めて11個ほど存在したので、それぞれにTRIGGERを設定しました。設定したテーブルにINSERT, DELETE, UPDATEがあると、キューテーブルにスカウト対象者テーブルの主キーをインサートします。rakeタスクは30秒に一度の間隔でキューテーブルをポーリングし、更新の必要のあるスカウト対象者をMySQLから取得した上でOpenSearchへの更新を行うためのJSONを作成し、OpenSearchに更新を行います。
更新待ちキューに関して、以前は各アプリケーションからAWSのSQSを経由してデータを送信し、rakeタスクでポーリングする方式を採用していました。しかし、今回はSQSは利用せず上で述べたような方法を選択しました。この方法を採用した理由は以下の通りです:
- データ更新経路の多様性:弊社ではデータ更新経路が複数のRailsアプリケーション、複数のJavaアプリケーション、そしてトラブル発生時のデータメンテナンスのための生SQLに分かれており、各アプリケーションにキュー送信処理を組み込むのは実装のコストが大きい
- 「枯れた」技術の利用:既存の確立された技術の使用により、新たなリスクを回避できる
- ある程度のリアルタイム性:データ変更があった場合、即座にキューテーブルへの挿入が行われる
- トランザクション制御:データの更新とキューテーブルへのインサート処理がトランザクション内で完結するため、整合性が保たれる
この方法を採用するにあたって受容したデメリットは以下の通りです:
- DBシステムの複雑性の増加:トリガやコールバックを大量に導入することはDBシステムの複雑性を増加させるが、今回のトリガは変更があった時にログをインサートするだけなのでそこまで大きな問題はないと判断した
- スケーラビリティ:トリガを利用する方法は更新が多くなるとスケールが難しいが、大量にレコードを更新するような処理が連続することは現在の弊社のサービスではあまりないので問題は起きないと判断した。
- トランザクションによるロック:キューテーブルはINSERTとDELETEしか行わないテーブルではあるが、場合によってはテーブルにロックがかかりキューテーブルからのレコードの削除まで時間がかかることがあった(トリガによるキューのテーブルへのインサートを特定のバッチでのみ一時的に無効化することで対応できた)
今回は、他にもAWS Glueのような方法からAWS DMSやdebezeimなどのCDCまで、マネージドサービスを中心に色々な方法を検討していました。
特に注目していたのがMySQLのテーブルをキューとするのではなく、キューはAWSのSQSを利用して、Aurora MySQLの機能を利用してトリガからAWSのlambda functionをコールしてlambda functionからSQSにエンキューする方法でした。元々弊社ではキュー的なものを実装する時にはSQSを利用することが多く、この方法は有力な候補でしたが、lambda functionをコールしたトランザクションがCOMMITされた後にエンキューされるのではないことから本要件での利用は断念しました。一つのトランザクションの実行時間が長くlambda functionが実行される時に該当のトランザクションがまだCOMMITされていない場合や、該当のトランザクションが途中でロールバックした場合などに対応するのが難しいと思ったためです。
OpenSearchによる検索
スカウト対象者検索では、様々な検索条件に基づいて組み立てられたJSONを用いて、OpenSearchのsearch APIを通じて検索を行っています。具体的には、まずスカウト対象者の主キーをOpenSearchから取得し、その後、Auroraデータベースから表示に必要なデータを取得します。
元々の実装では、複数のSQLクエリを順番に実行して主キーを絞り込む実装になっていましたが、OpenSearchの導入により、検索プロセスが大幅に簡素化されました。具体的には、一回のOpenSearch検索で必要な全ての主キーを絞り込み、その結果を使用して迅速に検索対象のスカウト対象者のリストを取得できるようになりました。
今回は、既存のMySQLベースの検索機能をOpenSearchに移植し、その高速化に重点を置いています。OpenSearchの機能を最大限に活用すれば、これまで不可能だったより高度な検索機能も実現可能ですが、今回は元の機能の移植とパフォーマンスの向上に注力しました。
テスト中に発生した問題
テスト中に遭遇しましたいくつかの問題のうち、主な2つが以下になります。
1つ目はcompressionというオプションの適用問題です。
OpenSearchではデータ更新や検索リクエスト時にcompressionというオプションを使ってリクエストをg-zipで圧縮することが可能です。
今回はこれを有効にしようと思って開発を進めており、ローカル環境ではこの設定を有効にしても問題なく通信できましたが、設定の問題か何かでAWS上のテスト環境ではエラーが発生しました。
リリースの優先度を考慮し、今回はcompressionオプションの使用を諦め、圧縮なしでの通信を行うことにしましたが、将来的にはこの問題を改めて調査し、圧縮設定をオンにする予定です。
2つ目は、高負荷時の検索レスポンスタイムの劣化です。
前回のブログ記事「OpenSearch の導入による検索システム改善のための認証・認可設計と負荷検証結果」でも書いたのですが、OpenSearchではrefresh_intervalという更新内容を検索結果に反映するまでの時間を短くするほどパフォーマンスが劣化することは元々認識していました。
ただし前回の求人一覧のOpenSearch利用の際は、refresh_intervalをデフォルトの1秒のままでインスタンスサイズを増加させることでパフォーマンス問題を解決しました。
しかし、今回OpenSearchに新たなインデックスを追加し、再度負荷検証を行った結果、refresh_interval=1sで短時間に更新リクエストが大量に来る場合には一時的に検索のレスポンスタイムが著しく劣化することが分かりました。
そのため、今回新たにインデックスの更新リクエストが増えることや、今後さらに検索機能をOpenSearchに置き換えることまで考えて、既存のものも含めてrefresh_intervalを30秒以上に設定することにしました。
導入した結果
OpenSearch導入前後のスカウト対象者一覧のレスポンスタイムの日ごとの中央値の推移について紹介します。
まずは、検索条件を何も指定しなかった場合のレスポンスタイムの推移が以下になります。

10/18のリリース前は3秒強だったレスポンスタイムが0.5秒前後まで縮まりました。
検索条件を何も指定しなかった場合でも大きく改善しているのは、元々はページングのために検索結果にマッチする件数を取得するために数十万件のレコードがあるテーブルを複数JOINした上でCOUNT(*)を実行しており、そこがかなり負担になっていたのですがそこがOpenSearchに任せたことで数msで済むようになったのが大きいと思っています。飲食店ドットコムは20年ほど続いているサービスなので、実装時はパフォーマンスが問題にならなかったもののユーザー数の増加と共にパフォーマンス面で問題になるというケースが度々あり、今回もその一つでした。
次が、全文検索エンジンの本領発揮である、フリーワード検索を検索条件に含む検索の時のレスポンスタイムになります。

以前は1日ごとの中央値で6秒~12秒というレスポンスタイムでしたが、OpenSearch導入後は、検索条件がないときと同じ0.5秒ほどで推移しています。これはやはり元々が遅かったインデックスの効かないキーワードのLIKE検索を大きく高速化できたためだと思われます。また、フリーワード以外の検索条件を含んだものもここには入っているため、他にもFIND_IN_SETなどを利用したインデックスの効かない検索を高速化できたのも理由として大きいはずです。
導入した結論としては、以下のようになります。
- 検索条件が何もない時でも実行時間の大きかった件数表示のための
COUNT(*)をMySQL上で実行しなくて済むようになったことでレスポンスタイムが改善した - フリーワード検索を含むような複雑なリクエストは検索条件がない時に比べても大きくレスポンスタイムが改善した
まとめ
負荷軽減と高速化を目的に、スカウト対象者検索機能にもOpenSearchを導入しました。
更新方法についてはMySQLのトリガを利用して変更された内容をセミリアルタイムにOpenSearchに反映する形を取りました。
OpenSearchを導入した結果、検索クエリが単純な場合と複雑な場合で共にレスポンスタイムが大きく改善しました。
今回のスカウト対象者検索機能はMySQLでも改善が不可能ではないと思うのですが面倒な、COUNT(*)やLIKEやFIND_IN_SETをそれなりのレコード数のあるテーブルで利用しているページということもあり、OpenSearchの導入の効果は大きかったです。