こんにちは、シンクロ・フードの日下です。
最近は、健康のためラジオ体操を毎日の習慣にできるよう取り組んでいます。
シンクロ・フードでは、2022/10/05 の 05:00 から 08:00 の間、サービス停止を伴うサイトメンテナンスを実施し、Aurora MySQL の v1 (MySQL 5.6 互換) から v2 (MySQL 5.7 互換) へのアップグレードを行いました。 本記事では、アップグレードのために行った変更、またスムーズなテストのために工夫したことを記します。
なぜアップグレードしたのか
なぜなら、Aurora MySQL v1 のサポート終了が発表されたからです。
飲食店ドットコムを始め主要なサービスで Aurora MySQL v1 をメインの DB として使用しているため、対応が必要でした。
アプリケーション側の変更
シンクロ・フードでは、サーバーサイドでは以下のフレームワーク・言語を使用しており、それぞれ DB 接続用のライブラリの更新が必要か確認しました。
- Ruby on Rails (Ruby)
- Seasar2 (Java)
Ruby on Rails で使用している Mysql2 については、既に MySQL 5.7 と互換性のあるバージョンを使用しているため対応が不要でした。
Seasar2 で使用している MySQL Connector/J は、MySQL 5.7 未対応の 5.1.23 を使用していたためバージョンアップしています。
バージョンアップするバージョンは、MySQL 5.6、5.7 の両方をサポートする 8.0.27 を選択しました。
なぜなら、MySQL 5.6 がサポートされているため、Aurora MySQL v2 へのアップグレードより先にバージョンアップできるからです。
先にバージョンアップを行うことで、Aurora MySQL v2 へのアップグレード当日の手順を減らせます。
また、Aurora MySQL v2 へのアップグレードで問題が発生した場合も、素早く v1 へロールバックできます。
インフラ側の変更
インフラ側の変更で 1 番悩んだ点は、アップグレード方法の検討でした。
検討していた時 ANDPAD 様の以下の記事を読み、アップグレード当日の作業を最小にできる事からシンクロ・フードでも binlog レプリケーションを使った Blue-Green Deployment を採用しました。
CNAME を使ったエンドポイントの指定や、ROW_FORMAT の変更に伴う長い DDL の実行など、とても参考にさせていただきました。
ANDPAD 様、素敵な記事をありがとうございます!
また、具体的な手順については、以下の AWS の記事を参考にしています。
アップグレード後は、Aurora MySQL v2 から v1 への逆レプリケーションを設定して、万が一の際は素早くロールバックできるようにしています。
新しいバージョンから古いバージョンへのレプリケーションは公式にサポートされていませんが、事前にテスト用の環境で問題が発生しないことを確認しました。
テスト
シンクロ・フードでは、社員しかアクセスできないテスト用の環境を用意しており、開発中の機能のテストを行っています。
Aurora MySQL v2 についても、テスト用の環境でアップグレードを行いテストしました。
テストではエラーにならないことの他に、パフォーマンスが劣化しないことを重視しました。
しかし、パフォーマンスのテストと言っても、ただページへアクセスするだけでは Aurora MySQL v1 と比較して劣化しているかどうかの判断は難しいです。
また、影響する範囲が広く、SQL を 1 つ 1 つ確認するのは時間がかかりすぎると考えました。
そこで、HTTP リクエストを実際に送信し、ログから実行された SELECT 文を取得して、Aurora MySQL v1 と v2 で比較するテスト用の機能を作成しました。
以下の図が、機能の概要です。
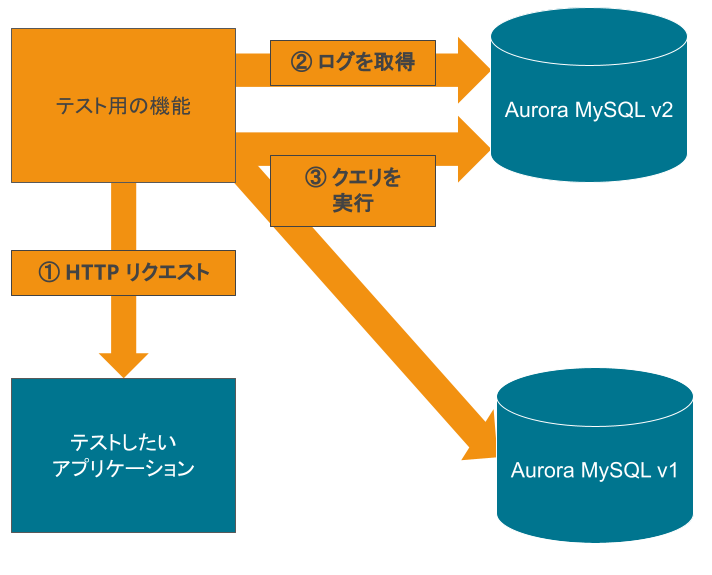
- まず、テストしたいアプリケーションに対して HTTP リクエストを送信します。
- HTTP リクエストの送信時刻とレスポンスが返ってきた時刻で処理時間を計算し、処理時間中のログ (general log) を Aurora MySQL v2 から取得します。
- 取得したログから SELECT 文を抜き出し、Aurora MySQL v1 と v2 に対して実行して結果を取得します。
SELECT 文の EXPLAIN も実行して、実行計画も同時に取得します。
実際に、テスト用の機能で表示される SELECT 文の比較結果の一例が以下になります (お見せできない部分は黒塗りしています)。
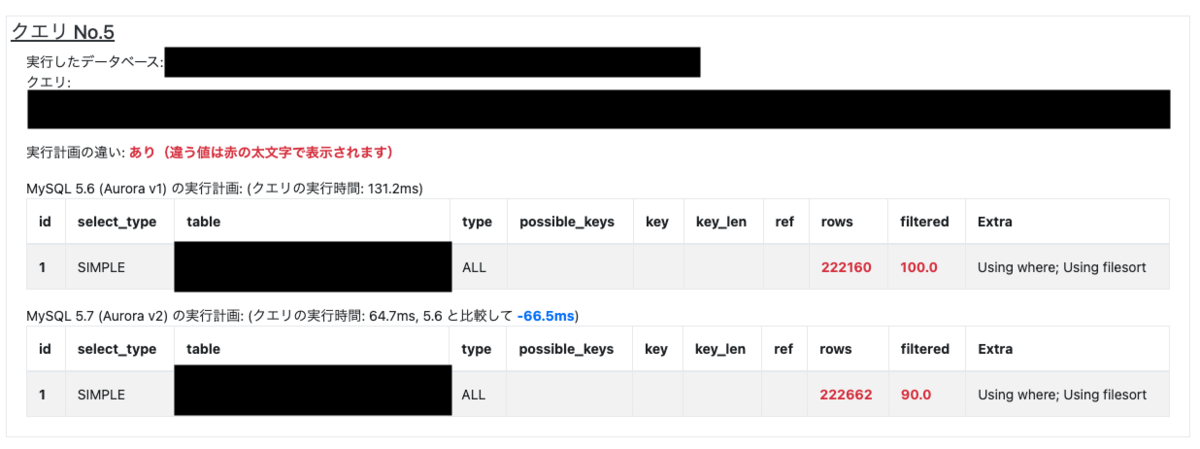
Aurora MySQL v1 と v2 の実行計画を表示しており、差がある箇所は赤色の太文字で強調しています。
また、Aurora MySQL v1 と v2 での SELECT 文の実行時間の差を表示、参考できるようにしました。
EXPLAIN の実行計画を比較することで、DB の負荷などを考慮せずにパフォーマンスが劣化しているか確認しやすくなりました。
さらに、テスト用の環境でも Aurora MySQL v2 から v1 へ逆レプリケーションを実施していたため、同じデータ量で比較ができています。
このテスト用の機能と EXPLAIN の見方を各サービスの開発者へ案内することで、スムーズにテストを行えました。
テスト方法はどんなアップグレードでも悩む点ですが、今回はユニークな方法で上手くテストできたと考えています。
リリース
テストが完了し、2022/10/05 の 05:00 から 08:00 のサイトメンテナンスでアップグレードを行いました。
アップグレードについては、Blue-Green Deployment によって Aurora MySQL v1 から v2 へ接続先を切り替えるだけということもあり、無事メンテナンス時間内で終えることができました。
アップグレードしてから、もうすぐで 1 ヶ月経ちますが現在まで大きな障害は発生していません。
まとめ
無事に Aurora MySQL v1 から v2 へのアップグレードを行えました。
本記事が、アップグレードへ取り組んでいる方や取り組もうとしている方の、お役に立てれば幸いです。
最後に、エンジニア募集のお知らせです!
シンクロ・フードでは、今回の Aurora MySQL アップグレードに限らず、まだまだ技術的な課題やチャレンジが残っています。
ぜひ、一緒に改善していきましょう!
また、飲食店ドットコムを始めとしたサービスの開発・改善も、どんどん進めております。
ご興味のある方は、以下の採用サイトからご連絡ください!
www.synchro-food.co.jp





