初めまして。シンクロ・フード開発部の横山朋玖です。
今日の記事は、RubyKaigi 2023に参加した横山のRubyKaigi 2023の参加レポートになります。
なお、こちらの記事は前編になります。前編では、RubyKaigiとは何か、RubyKaigiに参加した動機、RubyKaigi 2023で印象に残ったセッションや、技術的に刺激を受けたことなどをまとめられればと思っております。
そして後編は、前編には書ききれなかったRubyKaigi 2023での多くの出会い、出会いを通して学んだこと、得られた経験、そしてRubyKaigiの素晴らしさなどをありのままに書き記したレポートになります。よろしければ後編もご覧ください。
自己紹介
Ruby(Rails)を使って弊社のWebサービスを開発して一年半目の横山朋玖です。 弊社のサービスである求人飲食店ドットコムの開発を行っています。
また、趣味で英会話レッスンにも一年ほど通っております。
RubyKaigiとは?

RubyKaigiとは日本で毎年開催されている、Rubyに関する技術イベントのことです。ここ数年はパンデミックの影響でオンライン開催が続いていたようですが、RubyKaigi 2022からは現地での開催が再開しました。
そしてRubyKaigi 2023には、Rubyを利用している開発者をはじめ、三日間で約1500人ほどにものぼる多くの方が世界中から日本に集まりました。
RubyKaigiは、Ruby開発者同士の繋がりをより強め、コミュニティを活性化させるために年次で開催されるイベントです。
そのため、会場にはRuby開発者が馴染みのあるRubyネタがあちらこちらに散りばめられており、ネタには思わず笑ってしまうこともありました。
なお、これを読んでくださっている方の中の多くは、RubyKaigiをあまり知らない方がほとんどかと思います(実際私も去年まで知りませんでした)。
そこで、会場の雰囲気はこんな感じ!というのをいくつかの写真を通じ、簡単に共有できればと思います!
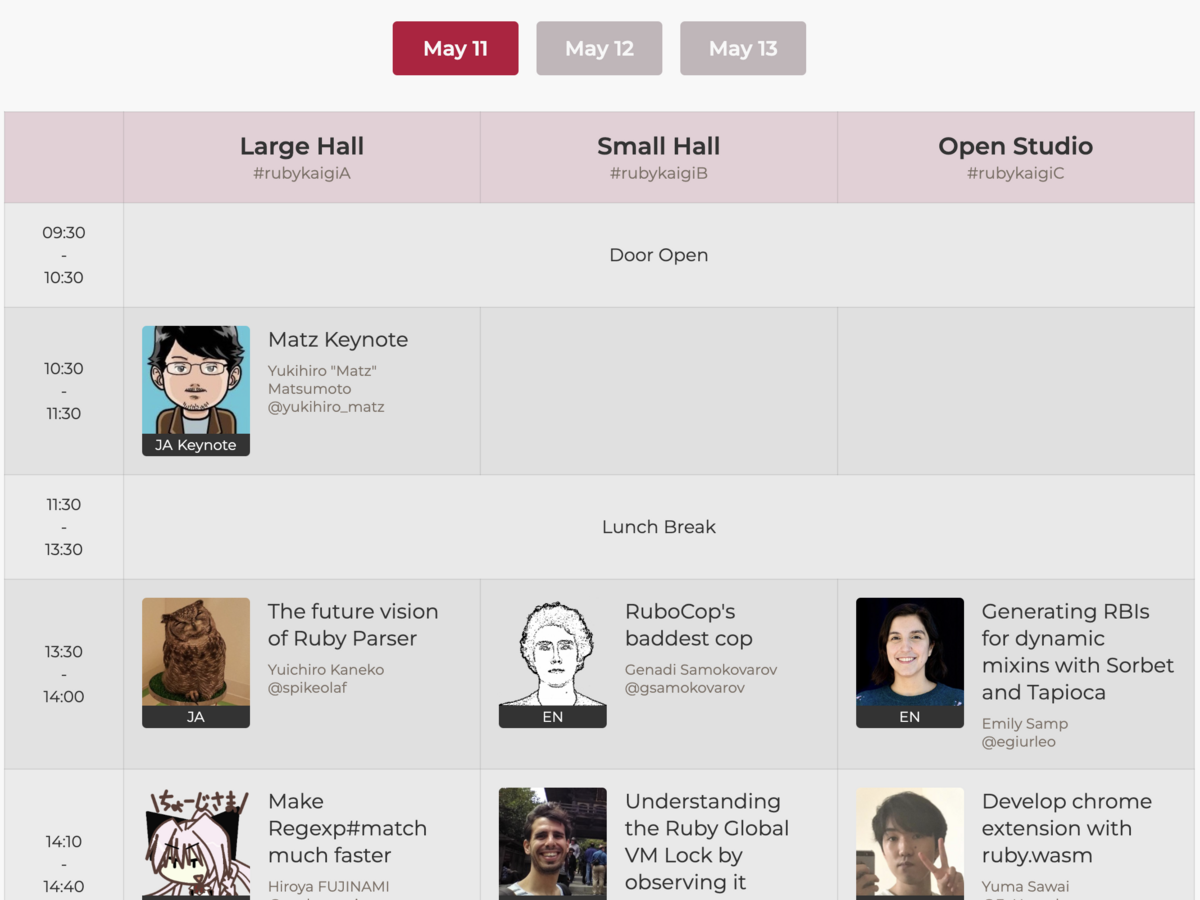
まずはこのイベントの醍醐味である、有名開発者によるセッションのスケジュールになります。
RubyKaigiでは、Rubyというプログラミング言語自体*1の開発者(この開発者のことを、Rubyコミッタと呼びます)や、Rubyコミュニティに大きく貢献している開発者などによるセッションが多く開かれます。
なんと今回のRubyKaigiでは同時に三つのセッションが並列で開催されていました。
以下の画像は、私の尊敬する開発者の一人であるSamuel Williams氏による発表の雰囲気になります。
彼は、HTTPというWebプロトコルにまつわる問題提起、そしてその問題を解消するためにご自身が作成されたプログラムをセッションで発表されていました(詳しい内容については、本記事中のセッションについての紹介セクションをご覧ください)。

さらに、会場では多くのスポンサーがブースを開いていました。
ブースにて、スポンサーによるRubyKaigiオリジナルグッズの配布や、二日目にはブースを巡ってスタンプを集める「スタンプラリー」も開催されていたりと、スポンサー企業と関わることのできる機会が沢山ありました!
セッションが開催中の時間帯でもブースにはいつも人がいましたので、セッションが開催している時に敢えてブースに遊びに行ったり(もちろんガラガラ)、朝早くから会場に出向きブースに遊びに行ったりということもできました。
混んでない時間にブースに立ち寄ると、もちろんブースの運営開発者とより長い時間会話ができる嬉しさもありますが、それ以上に「(スタンプラリーやグッズを求める)1RubyKaigiの参加者」としてではなく「技術に興味のある1開発者」としてより深く交流できる嬉しさがありました。
私の場合、スポンサー企業に勤める開発者の方と技術的なお話をさせていただき、交流させていただきました。
例えば、弊社のリモートワーク上の課題を他社さんに共有してみたのですが、他社さんも同じ悩みを抱えていることがわかったり、逆に「こういうふうに弊社は取り組んでいます」という風なアドバイスをしてくださったりしました。
弊社にとって、また、私個人にとっても有益な情報をブースの交流を通してたくさん知ることができました。

さて。前述したように、スポンサー企業が当日配布されているRubyKaigiオリジナルグッズも紹介できればと思います。
私の一番のお気に入りグッズは、Findyさんにいただいた「なんもわからん付箋」でした(笑)。この付箋は裏表別の言葉が書かれており、表側には「完全に理解した」という言葉が書かれています。
ところで、実はこれらの言葉はエンジニア界隈の語録的なものです。「完全に理解した」という言葉はエンジニアがある分野について勉強を進め、少しその分野に詳しくなってきた時に良く口にします。分野全体の理解度が20% ~ 30%程度の時にこのように口にしている傾向が強いです。ソースは私です。
そして、分野の勉強を進めていくにつれ、当然理解できないこともまた増えていきます。壁にぶつかる度に、着実に理解度は「完全に理解した」時よりも増えているのに、自分の自信度は急降下していきます。そんな時エンジニアは「なんもわからん」と口に出し、自分の辛さを言葉で表現するのです。
この付箋はまさに、そういった「エンジニアあるある」を付箋として表現しています。私にとってとてもキャッチーな言葉に魅了され、愛用しています。

このように、三日間を通じて多くの開発者や企業からRubyコミュニティを盛り上げる催し物がたくさん行われました。
楽しすぎたあまり、ブースの様子を撮り忘れてしまいありのままの様子をお伝えできないのが少し残念ですが、これで少しでもRubyKaigiの雰囲気が読者の皆様に伝われば嬉しいです。
そして、なんとこのイベントには2018年、弊社から二人もの方が参加されたこともあります!
よければそちらの記事もご覧ください。
RubyKaigi 2018 に参加してきました (@fohte) - シンクロ・フード エンジニアブログ RubyKaigi 2018 に参加してきました (@n0_h0) - シンクロ・フード エンジニアブログ
なぜRubyKaigiに参加したのか?
Rubyは現在、多くの企業によってWebアプリケーションを作成するのに使われています。
そして、弊社も例外ではありません。弊社では、私の開発担当している求人飲食店ドットコムをはじめとする提供サービスの多くがRubyによって開発されています!
そしてRubyKaigi 2023では、前述したように世界中から約1500人ほどのRuby開発者が集まります。その中には日本の企業で働いている方、海外の企業で働いている方、プログラミング言語「Ruby」の生みの親である「まつもと ゆきひろ」さんをはじめとしたRubyの言語自体を作成している方、著名なRuby開発者なども参加されました。
会場の規模感や雰囲気は弊社エンジニアブログの過去の記事を見たりRubyKaigiの概要を調べたものの、正直あまりわかっていませんでした。
しかし、少なくとも私は「世界中から素晴らしい技術者が大勢集うKaigiである」ことは理解しておりました。そのため、私がRubyKaigiに参加した理由は、
RubyKaigi 2023に参加し、世界中の多くの人からできるだけ多くの、色々な種類のインスピレーション(モチベーション)を受けたい
からでした。
技術的なモチベーション、インスピレーションだけではなく、勉強に対するモチベーション、海外の人とお会いし英語に対するモチベーションなど、私が今の人生に必要だと思う全ての種類のモチベーション、インスピレーションが得れると信じ、私はRubyKaigiに参加しました。
そして結果的に、今回RubyKaigiに初めて参加し、私は日本人の中で最もRubyKaigiを楽しみ、一番多くの刺激を得られたと思えるほど、多くの経験や出会いをさせていただきました。そして、私の人生に今必要な全てのインスピーレーションをRubyKaigiにて得られたと心から感じています。
この記事では人との出会い、学んだ教訓、そして、どんな素敵な経験をRubyKaigiでしたのか?といったことは紹介しません。
そのような内容は【後編】の記事にてありのままを書きました。気になった方は、ぜひそちらの記事をご覧ください。
セッションの紹介
Make Regexp#match Much Faster
この発表は、正規表現のRubyコミッタであるHiroya Fujinamiさんによる発表です。
正規表現にはとても強い力があります。
例えば「"01 + 01 = 10"という文字列が二進数の足し算であるか?」を判定できたり、brainf**kインタプリタをRubyの正規表現で開発された方もいるように、とても強力です。
正規表現は強力な機能である一方で、大いなる力には大いなる責任が伴う(Fujinamiさんの発表中の言葉をお借りします)という言葉が示すように、正規表現には「弱点」があります。
この弱点は「ReDoS脆弱性」と呼ばれており、このReDoS脆弱性は現実世界でも問題になっています。例えば、あるサービスがReDoSが原因で27分間も使用不可能になってしまったり、RubyのGems(ライブラリ)で使われている正規表現にもReDoS脆弱性が存在していたりします。
この発表者のHiroya Fujinamiさんは、このReDoS脆弱性を引き起こしにくくするために、正規表現の性能を大幅に引き上げる修正をRuby 3.2.0で実装した方です。
彼は「正規表現の現状実装をどのように変えたらReDoS脆弱性を引き起こさないようにできるのか?」という問題に、「メモ化」と呼ばれる最適化手法を使い、正規表現の仕組みの最適化を行いました。
この発表では、開発時にどのようなことを考えていたのか、今後どんなことを実装していきたいか、という点についても発表をされていました。
感動したこと
一番感動したことは、Rubyの全ての機能は、誰かが作っているということを実感したことです。
今まではRubyという仕組み・言語を「便利だから」使っていたに過ぎなかった私ですが、RubyKaigiに参加し彼の発表を聞いた後、Rubyの全ての機能は世界中の開発者が試行錯誤の末に成し遂げた「成果物」であることを実感せざるを得ませんでした。
実感すると同時に、正直、今まではRubyを「神から贈られたギフト」のように捉えていました。この発表を聞いた後意識はガラッと変わり、「Rubyは人が、人のために作るもの」であると捉え直すことができました。
私も近い将来、Rubyに新たな機能を実装できるような開発者になれたら嬉しいなと思いました。
そして次に、彼のスピーカーとしての講演での話し方です。
ReDoSについても全く知らない、そして当然正規表現についての実装の詳細が何も分からない私でもわかるように、丁寧な説明をしていただきました。
その中で私は、彼の「全ての聴衆に自分の気持ち、開発に対する向き合い方、そして、正規表現の面白さを伝えたい」という気持ちが伝わりましたし、私はその思いに至極感銘を覚えました。
彼の発表をお聞きし、彼が日々向き合っている「正規表現」のように、「自分が強く開発したい、貢献したい」と思える、私の技術的な適所を見つけたいと思いました。
Hiroya Fujinamiさん、素敵な発表をしていただき、本当にありがとうございました!
Fix SQL N+1 queries with RuboCop
このセッションでは、ISUCONと呼ばれる「お題として与えられたWebシステムをどれだけ高速化できたかを競うコンテスト」に参加されているGo Sueyoshiさんが、「ISUCONで出題されるWebシステムの中の『長文SQL』からすぐにN+1問題が起きている箇所を見つけられるRuboCopを作りたい」という思いをきっかけに作成された、RuboCopルールについての紹介がされていました。

ISUCON本番時、上記のようなSQLからN+1問題を早く摘出するのは、急いでいるならなおさらとても難しいと私は思いますし、通常業務の中でも、SQLからN+1のような問題を見つけるのはとても時間がかかるものだと感じています。
その点、このリンターを使えば生SQL限定ですが、N+1問題を摘出することができるため、ISUCONにおいては勝率を伸ばすことに十分コミットするはずです。
そして、N+1問題を解消するRuboCopルール以外にも、いくつかのルールが紹介されていました(詳しくはスライドを参照してください)。
感動したこと
一番感動したことは、「Rubyでは、やろうと思えばなんでもできるんだな」 ということでした。
やりたいと思ったことを自分で開発できること以上に、開発者が嬉しいこと、誇れることはないと思います。私はそのように思っています。
そして実は、私が開発を始めたきっかけは「作りたいと思ったものが作れる人になりたい」からでした。 (最初に作成したツールは、まさに自分の欲望を満たすためだけに作ったプログラムでした。)
しかし、最近は「仕事のためのツール」としてプログラミングを使っているだけであり、自分の夢を叶えるために、自分が本当に作りたいと思ったものを実現するために、開発をできていませんでした。
そして、そんなことを考えることすらも忘れてしまっていました。
彼の発表を聞き、ずっと忘れていた、心の奥に閉じ込められていた開発者にとって一番大事な気持ちを思い出しました。
そして、発表を聞き続ければ続けるほど、どんどんとインスピレーションを感じ、まるでその気持ちを加速させるかのようにエネルギーが自分の周りからどんどんと集まってきました。
実はこの記事の執筆時点では実はもう気持ちがだんだんと失われはじめているのですが、やはり自分が感じた問題を自分の力でより良くできることはとても尊いことだと思いますし、今年何かを成し遂げたいと奮起できたので、忘れないうちにSlackのチャンネルは作成しました。

私もこれからRuby開発者としてのキャリアを積んでいくと思うのですが、その中で自分が少しでも感じた問題に敏感になり続け、直近で「Rubyを使い、自分が直面している問題の解決をしたい」と思いました。
Go Sueyoshiさん、本当に素敵な発表をありがとうございました!
Unleashing the Power of Asynchronous HTTP with Ruby
こちらのセッションの発表資料は以下のURLから入手可能ですので、皆さんも是非見てみてください!
このセッションでは、HTTPの30年の歴史の紹介、現状のRuby環境において、HTTP 2+をサポートするHTTPアダプター(HTTP ⇄ Rubyをサポートする機能)が少ないという問題の提起、その問題点を解決するためにHTTP/2をサポートするHTTPアダプター「Async::HTTP」の作成したことが発表されました。
そして将来的に(今年中に)Async::HTTPでHTTP/3のサポートも行うことが発表されました。
皆さんご存知のように、WebとHTTPは現在切り離すことができない関係になっています。そして、HTTPの初回リリースからは、今年約30年になります。
HTTPは最初こそはシンプルなものでしたが、時間が経つにつれどんどんと機能追加、改善がされていき、現在ではHTTP/3までバージョンアップがされております。
しかし、RubyではHTTP/2以上をサポートするHTTPアダプタ(HTTPを解釈できるプログラム)があまりないのです。つまり、バージョンアップしてパワーアップしたHTTPをRubyは十分に使いこなせていない ということになります。
それを解決しようとしているのが、本セッションの発表者であるSamuel Williams氏です。
一番感動したこと
彼のスライドには、素晴らしいアニメーションが多数埋め込まれています。そして、そのアニメーションはとても素晴らしく作用していました。特に、英語のネイティブではない私でも、彼のスライドを見るだけで伝えたいことが十分に理解できました。

アニメーションの素晴らしさ、そして、クリアで聞き取りやすい英語での発表にも感動しましたが、最も感動したのは、
彼の自信に満ち溢れた発表でした。
私はこの講演を聞く前、素晴らしい開発者とは単に「開発という領域において能力を発揮できる人」だと思っていましたが、この発表を聞き、
本当の素晴らしい開発者は、開発能力に長けているだけでなく、「自信に満ち溢れた、人としても素晴らしい人」であることを本当に感じました。
そしてセッションが終わった後、彼に質問をさせていただきました。彼は私一人に対して10分程にも渡って質問に真摯に回答してくださいました。
彼に回答をしていただいていた際、気付いたことがあります。
それは、素晴らしいライブラリ開発の裏には、私には想像できないほどの努力があるということです。
彼は発表の中で、「Async(彼の作ったライブラリ)はHTTP三十年の歴史の複雑さを10行のシンプルなコードで隠せるライブラリである」とおっしゃっていました。
ですが、ということはAsyncの開発の際、当然Samuel自身はHTTP三十年の歴史を知り、その複雑性に向き合う必要があります。さらに、他にもたくさんの課題があったはずなのです。
彼の発表では苦労話は一切出てきませんでしたが、私とマンツーマンで話してくださった時は開発時に辛かったことも教えてくださいました。
私もいつか彼のようになりたい。 本当にそう心から思わせてくれた、素敵な時間でした。本当に素敵な発表・素敵な時間をありがとうございました。

最後に
以上で【前編】は終了です。最後までお読みいただきありがとうございました! よければ【後編】も是非ご覧ください!
また、弊社ではRubyエンジニアを募集中です!詳しくは下記のサイトをご覧ください! www.synchro-food.co.jp
そして、今回のRubyKaigi 2023には旅費、交通費、会費などを全て経費でご負担していただきました。ありがとうございました。 弊社の福利厚生・制度の詳細は、以下のページをご覧ください。
*1:プログラミング言語もまた、何か別のプログラミング言語のプログラムなのです